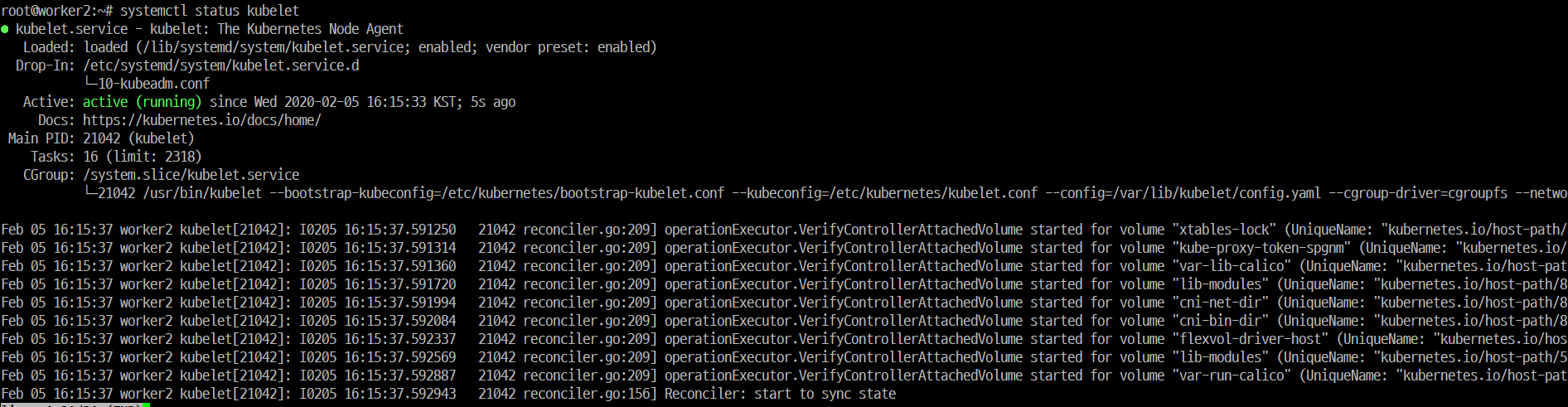
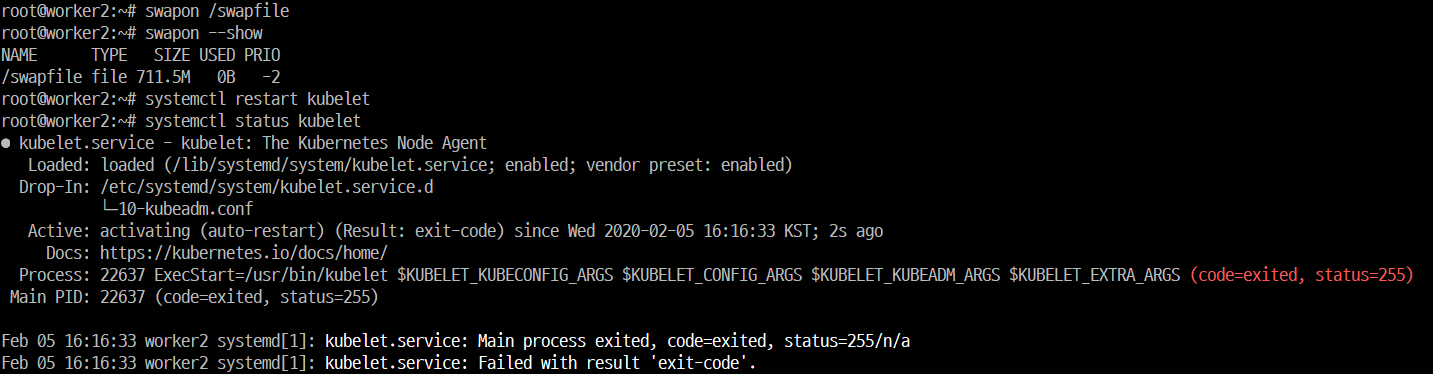
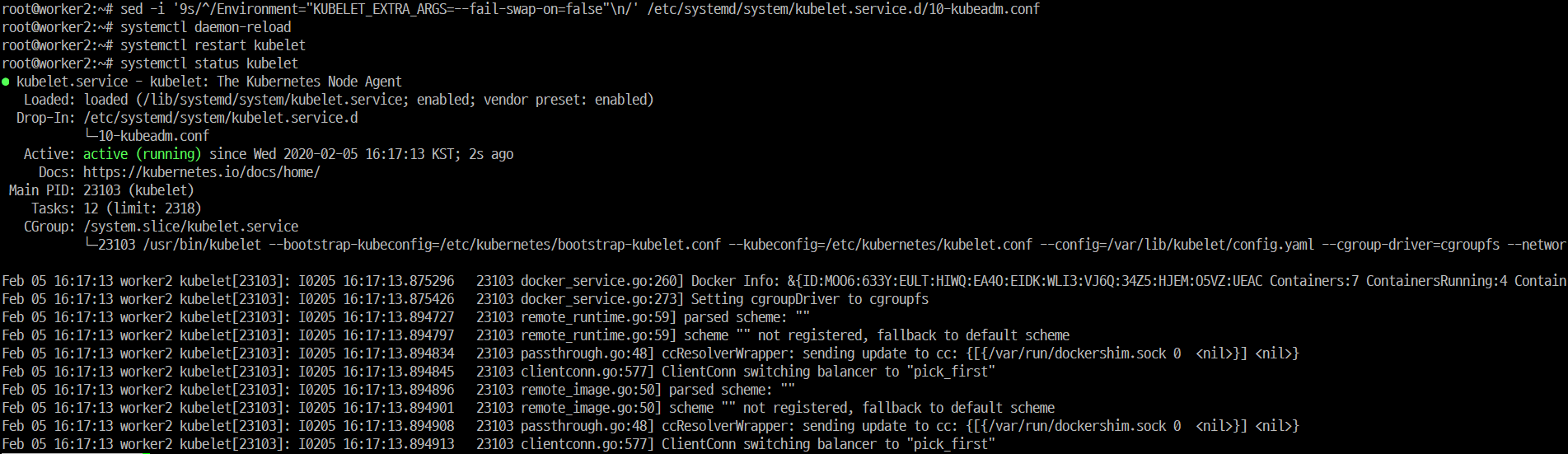
k8s의 probe를 istio가 어떠한 방식으로 변환하여 app의 health check를 수행하는 지 알아보자
k8s probe
k8s probe 종류는 3가지가 있다
- liveness
살아있니? 나 혹시 얘 죽이고 다시 띄워야 하니? - readiness
요청 받을 준비 됐니? 아직이면 얘 Service에서 지운다? - startup
잘 떴니? 그래 애가 좀 느릴 수도 있지. 다 뜨면 그 때부터 liveness, readiness probe 할게
probe 방법은 4가지가 있다
- exec
커맨드를 실행해서 exit code가 0면 성공, 그 외 실패 - httpGet
http response code가 200 이상 ~ 400 미만이면 성공, 그 외 실패 - tcpSocket
socket open을 시도해서 connection이 수립되면 성공, 아니면 실패 - grpc
k8s 1.24부터 베타로 적용 됨. grpc health checking protocol을 구현해야 함
probe 옵션은 다음과 같다
- initialDelaySeconds
- probe 최초 수행 지연
- default: 0 / min: 0
- periodSeconds
- probe 주기
- default: 10 / min: 1
- timeoutSeconds
- probe timeout
- deault: 1 / min: 1
- successThreshold
- probe가 몇 번 이상 성공해야 찐성공인지
- default: 1 / liveness랑 startup은 무조건 1 / min: 1
- failureThreshold
- probe를 최대 몇 번 수행할 건지
- default: 3 / min: 1
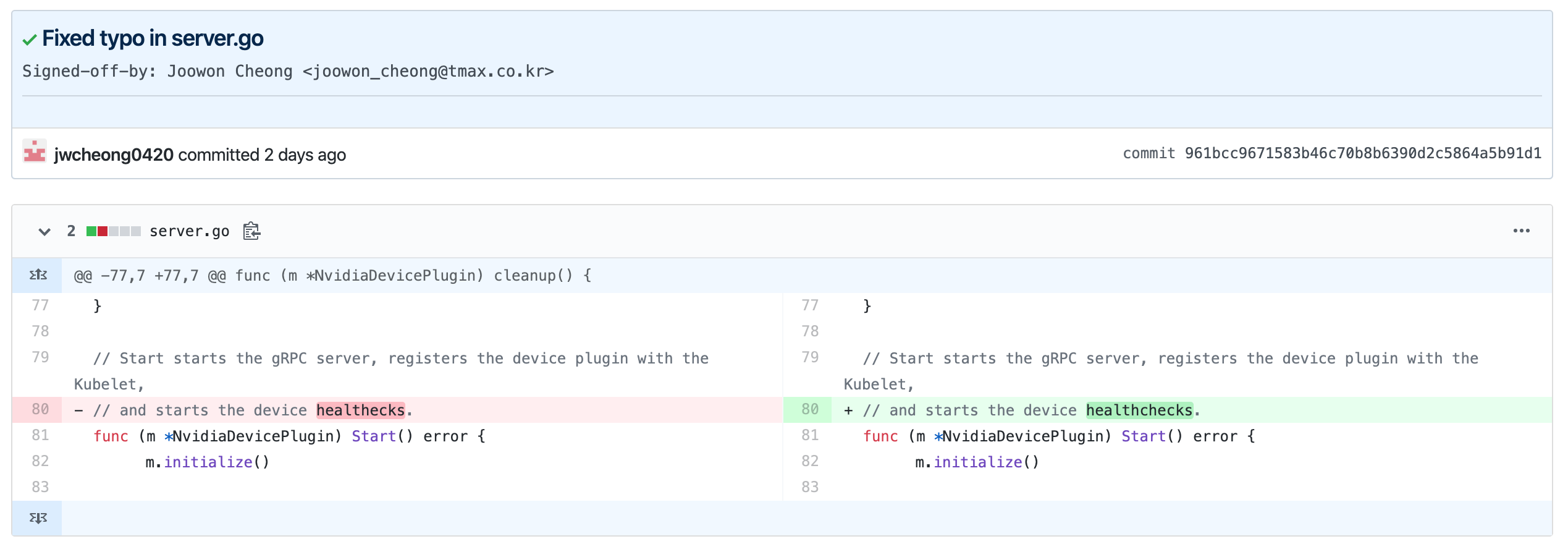
istio는 probe를 rewrite한다
그런데 주의할 점이 있다. probe는 kubelet이 수행한다.
The kubelet uses liveness probes to know when to restart a container.
For example, liveness probes could catch a deadlock, where an application is running, but unable to make progress.
Restarting a container in such a state can help to make the application more available despite bugs.
나는 service mesh를 지원하기 위해 istio를 설치하여 사용하고 있다
그런데 istio는 외부에서 container로 들어오는 트래픽을 sidecar로 redirect하며, kubelet이 보내는 요청도 마찬가지다!
http 요청의 경우 kubelet이 istio가 발급한 인증서가 없어서 실패할 수 있고(사실 뭔소린지 아직 모르겠음),
tcp 요청의 경우 모든 port가 open할 수 있는 것처럼 보여서 항상 성공한다
그래서 istio는 probe를 sidecar한테 보내도록 rewrite한다
Istio solves both these problems by rewriting the application PodSpec readiness/liveness probe, so that the probe request is sent to the sidecar agent. For HTTP requests, the sidecar agent redirects the request to the application and strips the response body, only returning the response code. For TCP probes, the sidecar agent will then do the port check while avoiding the traffic redirection.
tcp probe를 사용하는 예시
예를 들어 tcp probe를 사용하는 pod을 만들어보자
1 | apiVersion: apps/v1 |
생성해보면
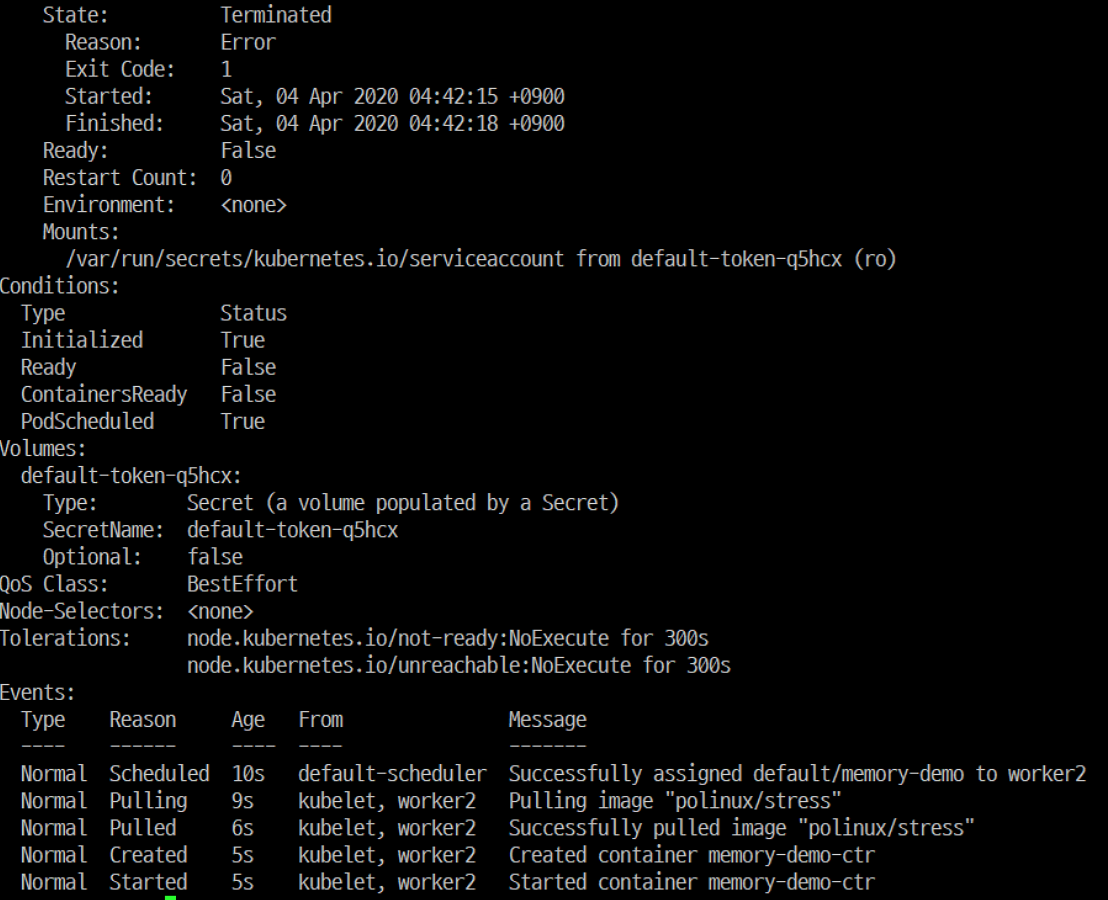
1 | $ kubectl describe pod probe-test |
test container의 liveness, readiness probe가 정의했던 것과 다르고,istio-proxy container의 환경변수에 ISTIO_KUBE_APP_PROBERS의 value로 우리가 하려던 probe의 내용이 들어가있다.
istio 소스에서 관련있는 부분을 찾아보니, 아래와 같다.
1 | // KubeAppProberEnvName is the name of the command line flag for pilot agent to pass app prober config. |
(내부 구현은 잘은 모르겠으나) /app-healthz/{container name}/livez로 요청이 오면 우리가 지정했던 probe가 실행되도록 해놓은 것 같다
rewrite하지 않도록 하는 방법
만약 이렇게 istio가 probe를 rewrite하는 게 싫다면spec.template.metadata.annotations에 sidecar.istio.io/rewriteAppHTTPProbers: "false"를 추가하면 된다
1 | apiVersion: apps/v1 |
생성해보면
1 | $ kubectl describe pod probe-test |
test container에 우리가 정의한 대로 liveness, readiness probe가 들어가있고,istio-proxy container의 환경변수에는 ISTIO_KUBE_APP_PROBERS가 등록되어있지 않다.
참고 자료
- https://kubernetes.io/docs/tasks/configure-pod-container/configure-liveness-readiness-startup-probes/
- https://istio.io/latest/docs/ops/configuration/mesh/app-health-check/#liveness-and-readiness-probes-using-the-http-request-approach